
From Cloud to Device: Quantized AI and the Future of XR

Introduction
Extended Reality (XR) – an umbrella term for AR, VR, and MR – is on the cusp of a major leap forward thanks to artificial intelligence. After years of parallel development, XR and AI are converging to unlock _spatial computing_ experiences that feel intuitive and transformative. Modern XR devices are finally equipped with high-resolution cameras and powerful on-board chipsets, while AI algorithms (from computer vision to large language models) have advanced dramatically. This convergence is viewed as a game-changer: Qualcomm notes that spatial computing is made possible by "the convergence of three key technologies: XR, on-device AI, and 5G". In other words, _now_ is the inflection point – the hardware, software, and AI smarts have aligned to enable XR applications that can see and understand the world in real time. Recent breakthroughs like generative AI (e.g. ChatGPT) have also primed consumers and developers to imagine AI-driven XR experiences. Major players are opening up previously locked-down capabilities (like access to passthrough cameras), signaling that the industry is ready to embrace AI-powered XR. In this post, we'll explore what this future holds, from a practical use-case to the technical underpinnings that make it possible.
Use Case Spotlight:
Imagine wearing an XR headset that not only guides you through a recipe, but also serves as your personal assistant in many aspects of life. For instance, in a kitchen setting, the headset's camera recognizes ingredients – eggs, flour, butter – and instantly suggests a recipe, guiding you through each step with overlaid instructions and visual cues. This isn't sci‑fi – prototypes have already shown that simply looking at ingredients can trigger an interactive cooking guide.

_Image suggestion_: An AR cooking assistant UI overlaying recipe steps and ingredient highlights in a modern kitchen.
But the possibilities extend far beyond the kitchen. The fusion of computer vision and AI guidance in XR can revolutionize many areas:
- Educational Tutors: Imagine an AR classroom where the headset identifies objects in a science lab, overlays detailed explanations, or even simulates virtual experiments in real time. A student could observe chemical reactions with safety, guided by AI that explains each step interactively.
- Industrial Training: In complex environments such as manufacturing or aviation, XR headsets can offer hands-free, real-time guidance. For example, during machinery maintenance, the system can highlight parts, provide step-by-step repair instructions, or simulate emergency procedures—all while ensuring safety and precision.
- Remote Assistance: Field technicians equipped with XR headsets can share a live view of their work with remote experts. The AI can analyze visual data, detect potential issues (using models similar to YOLO for object detection), and suggest corrective actions, drastically reducing downtime.
- Healthcare Support: In medical training or even during surgeries, XR can overlay vital patient data or procedural guidelines directly into the surgeon's field of view. AI models running on the device can monitor the procedure in real time, highlighting critical areas that require attention.
- Around 2018, TinyYOLO* and other compact detectors showed up, bringing object detection to mobile. By 2020-21, Ultralytics released *YOLOv5 with models of various sizes. The smallest, YOLOv5n (nano), is under 2M parameters, and the next one YOLOv5s (small) is ~7.5M params – tiny compared to the original YOLOv3 (which was ~65M). These smaller models trade some accuracy but can run at high FPS on edge devices. In fact, the AR cooking prototype mentioned earlier chose YOLOv5 precisely because it could "locate and classify multiple ingredients in one shot" efficiently, making the scanning process easier for users. Today's XR devices could run a model like YOLOv5s on each video frame and still maintain interactive frame rates, especially with hardware acceleration.
- The past couple of years have seen the rise of foundation models* – extremely large neural nets trained on massive data (for example, OpenAI's vision models or Meta's Segment Anything Model). These are powerful but **massive**. Meta's original **Segment Anything Model (SAM)** released in 2023 had a vision transformer with _632 million_ parameters – obviously not something you'd run on a headset locally. However, the response from the community has been to create distilled, efficient versions like **MobileSAM**. MobileSAM in mid-2023 showed that you can compress SAM's image encoder down to about _5 million_ params (using a Tiny ViT) and still get similar segmentation results. The entire MobileSAM pipeline is ~9.6M params (down from 615M) and runs in *12ms per image on a GPU. This kind of breakthrough means that even advanced tasks like zero-shot segmentation can be done on-device by using a small model. We're likely to see more "efficient SAM" and other efficient multimodal models that take the research-grade giants and squeeze them into leaner forms.
- For XR specifically, multimodal AI is on the horizon. Consider LLaVA* (Large Language and Vision Assistant), which combines a language model with a vision encoder. The original LLaVA used a 7B language model and a CLIP ViT-L encoder – far too heavy to run on an XR device. But a recent effort called *LLaVA-Phi showed a "proof of concept" by using a much smaller 2.7B language model (Phi-2) and optimizing the vision component, creating a compact multimodal assistant. It's still early, but it demonstrates the trend: taking large AI models and optimizing/quantizing them so that they can run at the edge. In a few years, we might have glasses that run a conversational vision model locally (likely leveraging specialized neural chips).
- Privacy – XR devices see and hear everything in your immediate vicinity. They literally have cameras pointed at your living space and microphones listening in. If all that raw data had to be sent to cloud servers for AI processing, it raises huge privacy concerns (and users would rightly balk at the idea of their headset streaming a live video of their home to the internet). On-device AI mitigates this by keeping sensitive data local. For example, with on-device object recognition, a headset can identify "keys on the table" without any image ever leaving the device. Unity Sentis notes that models run locally with "no data stored or transferred to the cloud". This not only comforts users, it can be essential for compliance in enterprise scenarios (imagine an XR headset on a factory floor – it may be forbidden to transmit video of certain machinery externally). Privacy is a fundamental requirement for wearables that are as personal as glasses, so on-device AI is the only viable path to many advanced features.
- Latency and Real-Time Feedback* – XR is interactive by nature. Whether you're playing an AR game or getting step-by-step instructions, the experience breaks if there's significant lag. If you move your hand and an AI is supposed to recognize your gesture, a 1-second delay is unacceptable – the feedback must be almost instantaneous to feel natural. On-device inference has the advantage of *zero network latency; it can often run in just a few milliseconds. By contrast, even a fast cloud API call might introduce 100ms or more of delay (not to mention if the network is spotty, that could blow up to seconds). In AR, _perceived latency_ is especially critical: if virtual content lags behind the real world motion, users feel nausea or discomfort. That's why, for example, Meta baked certain tracking AI models directly into the Quest's chipset – to achieve a 75% improvement in hand tracking latency. When you speak a command to an AR headset, you want the device to understand and respond immediately – local speech recognition can start yielding results within tens of milliseconds, whereas cloud speech might require you to finish speaking and then wait. In short, snappy AI equals good UX in XR.
- Offline and Edge Reliability* – A great benefit of on-device AI is that it works *anywhere, regardless of connectivity. If you take your AR glasses on a hike in the mountains, they could still identify plants or navigate trails for you without any signal. If you're in a secure lab with no internet, your MR training headset can still function. Relying on cloud can make an application brittle – no network, no service. With local AI, XR devices become more like true standalone assistants. They also avoid the issue of server dependency: even if the company backing the cloud service shuts it down, the device's core functionality can remain. This is analogous to why many prefer offline-capable voice assistants for home automation – it's just more dependable. For enterprise and military XR use, offline capability is often mandatory.
- Cost and Scalability – From a developer or company standpoint, using on-device processing can be more cost-effective at scale. If you had 100,000 users all streaming video to your cloud and running GPU-heavy models, you'd incur huge cloud compute bills. But if those 100k devices each handle their own processing, the marginal cost is borne by the consumer's hardware (which they've already paid for). It also scales naturally – as your user base grows, you don't have to exponentially grow a cloud backend. This isn't directly a user concern, but it influences what services can be offered sustainably.
- Thermal & Power Constraints – Running neural nets can be CPU/GPU intensive, which in a battery-powered headset means heat and battery drain. XR devices already have to drive high-res displays at 90Hz and track multiple sensors – adding AI inference on top can max out the system. Engineers have to optimize for bursty or efficient use of the processors so as not to overheat the headset or kill the battery in 30 minutes. This is why specialized NPUs and DSPs are important – they can do the work more efficiently. Still, developers might have to make trade-offs, like running vision models at a lower resolution or less frequently to conserve power. Techniques like _frame slicing_ (spreading a computation over multiple frames) are sometimes used to maintain frame rates. Thermal management is a hard limit: if a headset's chip overheats, it will throttle down and performance will drop. So part of on-device AI work is optimizing models to be _lean_ enough to sustain.
- Memory and Storage – Big models also consume a lot of RAM. A 600MB model simply might not fit in the memory budget of a headset that also needs memory for the game/app, the OS, etc. That's why model compression is crucial. XR devices often have between 4GB to 12GB of RAM total (Quest 3 has 8GB). Developers need to be mindful of not loading enormous models entirely to memory if possible, and may use techniques like lazy loading or smaller model variants for different contexts. Storage can be an issue too – if your AR app has to include a 1GB model file, that's a lot for users to download or for standalone devices with limited flash. The trend toward smaller models helps alleviate this, and quantized models can be a fraction of the size (e.g. int8 model is half the size of float16, etc.). In practice, most on-device models used in XR today are at most a few tens of MBs, which is manageable.
- Accuracy vs. Performance – There is often a trade-off between how _smart_ or accurate a model is and how fast/small it is. Developers must choose the right model for the job: e.g., a heavy vision model might detect fine-grained details but run at 5 FPS, whereas a lightweight one runs at 30 FPS but might miss some objects. In an XR context, a slightly less accurate but real-time model is usually preferable (since a delayed "perfect" detection might be useless if the moment has passed). That said, too low accuracy can also ruin the experience (if the cooking assistant constantly misidentifies ingredients, the user will get frustrated). Techniques like distillation aim to retain accuracy while shrinking the model. And there's also the option of hybrid approaches – do basic understanding on-device and occasionally consult a cloud AI for more complex queries. Finding the right balance is part of the art of designing AI-driven XR apps.
- Development Complexity – Integrating AI models into XR isn't entirely plug-and-play (though it's getting easier). Developers may need familiarity with ML tools to convert and optimize models for their target device. Debugging AI in an XR app can also be tricky – you have to test in varied real-world conditions, which is more unpredictable than a static input. Moreover, XR developers now have to consider not just game design or UI, but also dataset bias, model behavior, etc., which might be new to them. Frameworks like Sentis reduce some complexity, but there is still a learning curve in incorporating neural nets into an interactive 3D application.
- Meta Quest (Quest 3, Quest Pro)* – Meta's latest standalone headsets sport high-resolution outward cameras and a dedicated _passthrough_ mode for mixed reality. Quest 3, for example, has dual 4MP color cameras and a depth projector, enabling realistic AR overlays onto your real world. In 2024, Meta finally unlocked the **Passthrough Camera API** for developers, which (with user permission) grants access to the raw stereo color camera feed. Previously, developers could only use system-provided features (like hand tracking or a pre-meshed room geometry), but now they can feed the live camera frames into their own computer vision models. This means on-device object detection, image recognition, and more are possible in real time. (As an example, Meta suggests apps could scan QR codes, detect game boards on a table, or recognize physical objects for training scenarios.) The API is currently experimental on Quest 3, with Meta requiring a special flag (and not yet allowing these apps on the official store until the kinks are worked out). But it's a huge step forward. The Quest's underlying hardware is up to the task too – the Snapdragon *XR2 Gen 2 chipset in Quest 3 offers _4× the AI processing power_ of its predecessor, with a dedicated Neural Processing Unit (NPU) delivering up to 4x peak AI performance (8× per watt when using INT8 precision). This vastly improved AI horsepower "can be utilized to enable new use cases, such as dynamic object recognition and scene classification" on-device. In short, Meta's devices now have both the _eyes_ (color cameras) and the _brain_ (AI chip + APIs) to let developers create AI vision features in XR.
- Pico (Pico 4 Enterprise & Ultra)* – Pico, owned by ByteDance, has also been pushing the envelope in mixed reality. The **Pico 4 Enterprise** headset features dual 16MP RGB cameras, and the new *Pico 4 Ultra upgrades to dual 32MP passthrough cameras plus an infrared depth sensor. This gives Pico 4 Ultra an impressive ~20.6 PPD (pixels per degree) passthrough quality, slightly higher than Quest 3's ~18 PPD – enough to read text on a phone or a recipe card through the headset. Importantly, Pico has made camera access available (with some restrictions) for enterprise developers. As XR blogger _SkarredGhost_ noted, Pico actually _allowed_ passthrough camera access on its enterprise headsets even before Meta did, albeit in approved B2B use cases. Pico provides an SDK (the PXR API for Unity) that lets developers grab the passthrough images and integrate their own vision processing. In fact, Pico collaborated with developers to showcase this: in one demo, a Pico headset used the cameras and an AI model to play a Pictionary-style game, guessing what a user was drawing on paper in mixed reality. This shows Pico's intent to enable AI+XR experiments. While Pico's camera API might not be fully open to consumer app developers yet, the company clearly sees on-device AI as key for enterprise XR. With hardware parity (the Pico 4 Ultra also uses the Snapdragon XR2 Gen 2 chip and even bumps RAM to 12GB for extra headroom), we can expect Pico to continue expanding camera-based AI capabilities in their ecosystem.
- Apple Vision Pro* – Apple's upcoming MR headset (visionOS) is arguably the most sensor-packed device, with **12+ cameras** (for environment, eye tracking, hand tracking) including high-fidelity color passthrough. However, Apple takes a very privacy-centric, walled-garden approach. By default, visionOS apps do _not_ get direct access to raw camera feeds – Apple provides processed scene information (like a mesh of the room, or identified landmarks) but keeps images shielded. There is a special enterprise program where Apple *"gives enterprise companies raw access to Vision Pro's passthrough cameras" for internal apps, but only with a special license and only in business settings. This indicates the capability is there, but Apple is cautious about exposing it publicly. Nonetheless, Vision Pro will undoubtedly leverage on-device AI extensively for its own features (like eye-tracking, gesture recognition, and likely object detection within Apple's frameworks). We might see Apple relax camera access for developers in the future, especially if competitors forge ahead, but for now Apple's vision of XR+AI is more behind-the-scenes. Still, the sheer horsepower of the Vision Pro (with dual M2 and R1 chips) means it can run very advanced AI models locally – Apple has demonstrated impressive scene understanding and even hinted at "Apple Intelligence" features coming to the device.
- HTC Vive XR Elite* – HTC's standalone XR headset (XR Elite) also features a *full-color RGB passthrough camera for mixed reality. HTC has been working with the OpenXR standard and its own Wave SDK to support MR features. Developers can enable passthrough in Unity simply by configuring the camera background, indicating that the XR Elite's SDK supports blending the camera feed into apps. However, true _raw_ camera access for custom CV seems limited so far (HTC's focus has been on using the color feed for see-through AR and VR/MR streaming from PC). The XR Elite's color camera is high-quality (users report you can even read phone screens through it), so it's likely a matter of time before HTC provides richer computer vision APIs. HTC did announce updates like a Marker Tracking SDK and other developer features in mid-2023, which hint at computer-vision-based capabilities. While not as publicized as Meta's efforts, Vive XR Elite's hardware makes it capable of AI-driven MR – developers can already do things like run Unity's AR Foundation or OpenXR to anchor virtual content to the real world using the cameras. The hope is that HTC will expose more of the feed to developers or offer its own on-device AI modules.
- Sony PlayStation VR 2* – Sony's PSVR 2, a console-tethered VR headset, includes front cameras primarily for inside-out tracking and a passthrough view. Its passthrough is *black-and-white only and meant for basic situational awareness (finding your controllers or avoiding obstacles). There is no official mechanism for PSVR 2 developers to do AR overlays or run custom CV – the PS5 platform is closed, and Sony has not signaled interest in turning PSVR 2 into a mixed reality device. That said, the hardware _could_ potentially be used for some AR tasks (the tracking cameras see the room), but without access or color data, it's quite limited. Sony seems focused on pure VR gaming for now, so PSVR 2 is the least likely of these devices to be part of the on-device AI trend (aside from any AI that runs on the PS5 for graphics or foveated rendering).
In all these cases, the headset's outward-facing cameras act as smart eyes, while AI models provide spatial understanding—whether it's detecting an ingredient, identifying a malfunctioning part, or overlaying educational content. The system can personalize experiences by integrating generative AI to tailor responses and tips based on real-time context. This blend of on-device vision and AI isn't limited to cooking assistants—it's a gateway to smarter, more interactive environments across many fields.
By enabling immediate, hands-free interaction and real-time feedback, XR devices become truly _spatially aware_ assistants that adapt to various scenarios—boosting productivity, enhancing learning, and improving safety.
Shrinking AI Models: How Quantization is Powering the Future of XR
Model quantization* is a technique for compressing neural networks by reducing the precision of their parameters and operations. For example, instead of 32-bit floating point weights, a quantized network might use 8-bit or 4-bit integer values. By sacrificing a bit of numerical precision, quantization can dramatically **decrease model size** and computational cost. _How dramatic?_ A large language model like Llama 3 (8B parameters) can drop from ~32 GB in FP32 format to about 8 GB with INT8, and even down to ~4 GB with INT4. In practice, this means big models that once needed cloud servers can be squeezed to fit on *devices with limited memory and power – all while maintaining very similar accuracy to the original.
Why Quantization Matters for XR Devices
_XR devices like the Meta Quest 3 rely on mobile chipsets (e.g. Snapdragon XR2 Gen 2) that greatly benefit from INT8 optimized AI, delivering up to 8× better per-watt performance than previous generations. XR wearables – whether a standalone VR headset or AR glasses – have strict power and thermal limits. They can't house giant GPUs or endless battery capacity, so efficiency is king._
Positive Trends and What's Next

The trend toward quantized models in XR is only accelerating. High-performance int8 is now standard in mobile AI toolkits, and the industry is rapidly embracing 4-bit and even 2-bit* precision for next-gen efficiency gains. Research from Qualcomm and others shows that 4-bit quantization can often preserve accuracy with proper calibration or training adjustments, delivering up to ~*90% higher throughput and ~60% better power efficiency compared to already-optimized int8 models. This suggests that future XR hardware will likely include dedicated support for low-bit arithmetic (some current chips already tout INT4 acceleration), making ultra-compact neural networks even more mainstream.
Another promising development is the toolchain around quantization: techniques like post-training quantization* and *quantization-aware training have matured, allowing developers to compress models without manual trial-and-error. For XR developers, this means you can take a state-of-the-art vision or language model and convert it to a quantized version that runs smoothly on a headset or glasses. Meta's release of quantized Llama models (in partnership with chipset makers) is a strong signal – enabling these models on devices empowers new AI-driven XR applications, from offline digital assistants to real-time language translation in AR.
Moving forward, we can expect increasingly powerful AI on our face-worn devices*. Imagine next-generation AR glasses running a local **GPT-grade assistant** or performing live 3D object recognition around you – all without offloading to the internet. This vision is becoming plausible as model quantization techniques improve and XR processors are built to handle low-precision AI efficiently. In short, quantization is turning what was once science fiction (real-time, on-device AI in a pair of glasses) into an approaching reality. For XR developers and enthusiasts, it's an exciting time: these lighter, quantized neural networks are the key to unlocking *responsive, intelligent XR experiences that are truly untethered and ubiquitous.
Unity Sentis and On-Device ML Models

How can developers actually _bring_ AI into XR experiences? That's where tools like Unity Sentis* come in. Unity Sentis is a neural network runtime/inference library built into the Unity engine, allowing devs to run ML models locally in their Unity apps (which include many XR apps). In essence, Sentis lets you take a trained AI model (exported as an ONNX file, for example) and embed it into a Unity scene, connecting the model's inputs/outputs to your game or app logic. This is a big deal for XR: it means your app can incorporate capabilities like image recognition, pose estimation, speech transcription, etc., *without needing a server. The models run _on the end-user's device in real-time_. Unity emphasizes that Sentis "leverages the compute power of end-user devices rather than the cloud, which eliminates complex cloud infrastructure, network latency, and recurring inference costs". Especially for XR, which is meant to be untethered and responsive, on-device inference is the way to go. By running AI on the headset/phone, you get instantaneous results (no round-trip to a server) and you preserve user privacy (camera images never leave the device).

Unity Sentis supports all Unity platforms, meaning it can run on standalone VR headsets (like Quest or Pico running Android) as well as mobile or PC. It's quite optimized: it can use the device GPU or CPU, and Unity's Burst compiler and job system, to get the ML model running at _game speed_. For XR devs, this means you can do things like: run an object detector on the passthrough camera frames each update, or use a neural network to estimate the user's skeletal pose, or even run a small language model to power NPC dialogue – all within the headset, in sync with your virtual content. Unity provides sample use cases, such as object identification* with the device camera and *depth estimation from an AR view, directly illustrating XR scenarios. The integration is fairly straightforward: you import the model file into Unity, use Sentis to execute it, and then use the outputs (for example, a list of detected object labels and positions) to drive your AR visuals. And Sentis is not the only option – there are other libraries like TensorFlow Lite, MediaPipe, and Apple's CoreML that can be used in XR apps depending on platform, but Sentis is nice in that it's engine-agnostic and cross-platform.
One concrete pipeline could look like this: the XR app grabs a camera frame (using the platform's camera API as discussed above), feeds that image matrix into a Sentis model (say a CNN that segments the image), gets results (e.g. a mask of where the "bowl" is on your counter), and then uses Unity's rendering to overlay a highlight around the actual bowl in your passthrough view. All of this happens in milliseconds and entirely on the headset. Unity Sentis makes it feasible by handling the low-level optimizations. It even supports model quantization and other tricks to ensure performance is high. The benefits for developers include not just speed, but cost and scalability – you don't need to maintain cloud GPU servers for your app's AI features. And for users, the experience is seamless and works offline.
To illustrate, consider again the cooking assistant: Using Sentis, a developer could integrate a YOLOv5 model trained to recognize foods. Once the Meta Quest's Passthrough API provides the camera frames, the model (running via Sentis) identifies the ingredients on the fly. The Unity app then spawns AR highlight labels next to each real ingredient (e.g. "Tomato" above a tomato). Next, a prompt is sent to an on-device language model (or a lightweight cloud call if needed) to pick a recipe using those ingredients, and the steps are then displayed as an overlay UI. All interactions – scanning, recognizing, instructing – happen with low latency. Meta actually demonstrated something along these lines at Connect – and their Presence Platform will likely offer samples combining the Passthrough API with Sentis for object detection. In fact, Meta's documentation even describes using Sentis with the Passthrough cameras to perform custom computer vision.
_Flow of an AI-powered AR cooking assistant (prototype): The AR headset's built-in cameras and hand gesture input are used for ingredient scanning (using a YOLOv5 vision model), then a suitable recipe is recommended based on recognized ingredients, and finally a step-by-step demo is presented in XR. This illustrates how an XR device can go from camera input → on-device ML → AR guidance._
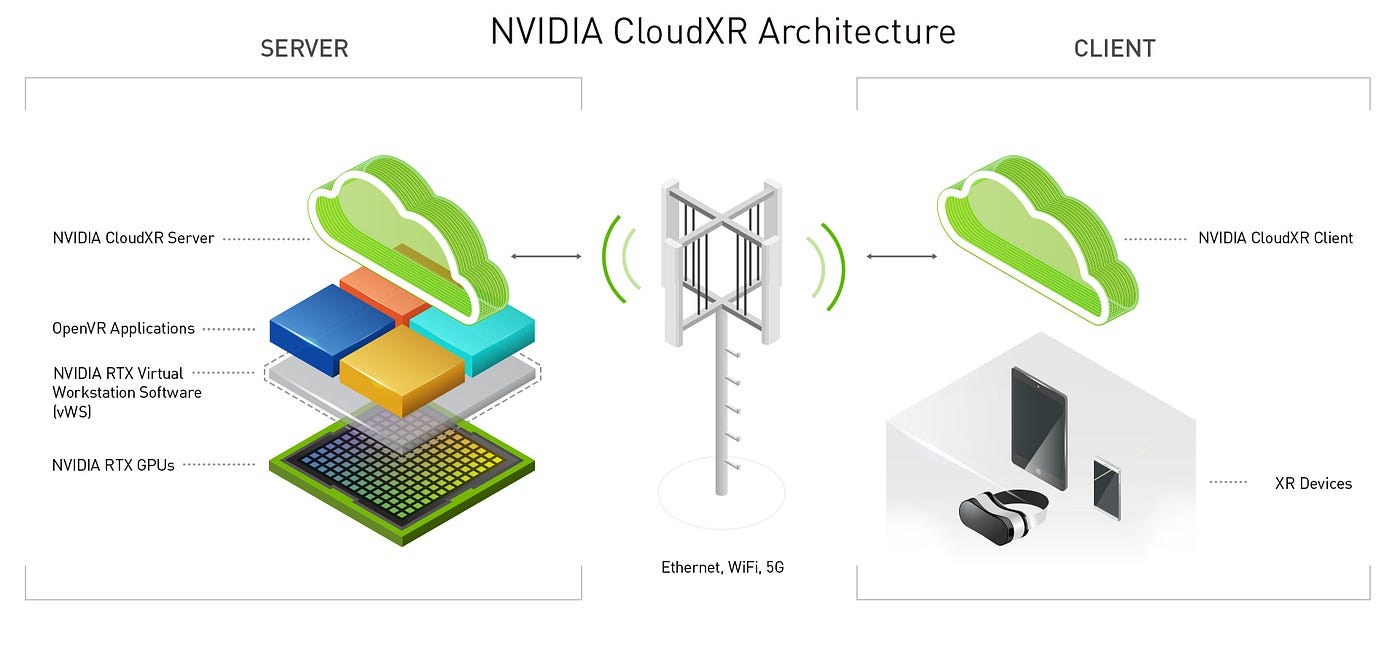
Beyond Unity Sentis, there are other notable tools for on-device AI in XR. For example, NVIDIA is pushing CloudXR* and GPU-driven edge solutions for high-end XR streaming with AI, and open-source projects like *ML Agents (for AI-driven game characters) can also tie into XR. But for most XR developers today, Unity Sentis (or Unreal Engine's upcoming analogous features) will be the gateway to integrate custom AI models. It's worth noting that Sentis is part of Unity's broader AI strategy (which also includes Unity Muse for content creation). The takeaway here is that the _plumbing_ to bring AI models into XR apps is increasingly available and developer-friendly. You don't have to reinvent low-level SDKs – the engines and platforms are providing the bridges.
Shrinking AI Models: Performance and Trends
One of the challenges with running AI on a headset or phone is that these models need to be lightweight and fast. Early deep learning models were huge and needed datacenter GPUs – but the industry has made big strides in shrinking AI models to run at the edge. Let's take a quick tour through this evolution and where things stand for XR:
_Comparing the size of various AI models over time (in millions of parameters). Early mobile-friendly models like MobileNetV2 (2018) had only ~3–4M params, and by 2021, YOLOv5s had ~7.5M. In 2023, Meta's Segment-Anything Model (SAM) introduced a massive ~600M-param vision model, but efficient versions like MobileSAM brought that down to <10M while remaining effective. This compression of models is crucial for on-device XR applications._
As the chart above illustrates, the trajectory hasn't been simply linear – we had a period of _widening_ models for the sake of generality (to achieve tasks like "segment anything" or image-captioning with near-human flexibility, researchers blew up model sizes into the hundreds of millions or billions of parameters). But now there's intense focus on bringing those capabilities to devices through model compression, pruning, distillation, and better architectures. Techniques like quantization* (using 8-bit or 4-bit weights) can drastically reduce memory and computation needs, often with minimal loss in accuracy. Qualcomm's XR2 Gen 2 NPU, for instance, is optimized for int8 execution, giving that 8× efficiency boost. There's also **sparsity** and *neural architecture search to trim unnecessary connections. The end result is that state-of-the-art vision models that would have been impossible to run in real-time on a battery-powered device a few years ago are increasingly within reach.
In practical terms, the current state-of-the-art for on-device vision in XR means you can expect to run models on the order of 5–15 million parameters comfortably at real-time (30+ FPS) on headsets and phones. Models in the 50–100M range might run at lower frame rates or with the help of optimization and better hardware (or asynchronously for things that don't need every frame). And anything larger than that usually requires either cloud offload or significant optimization/accelerator support. The great news is that each new generation of XR hardware is improving this balance. We saw Quest 3 double its GPU performance and quadruple its NPU power; Apple's Neural Engine in its M-series chips can do >15 trillion ops/sec; and companies like Google and Qualcomm are designing SOCs explicitly with AR glasses in mind that prioritize AI tasks.
It's also worth noting that _perception_ tasks (vision, audio) aren't the only ones getting lighter – even large language models are being trimmed for edge use. We now have 7B-parameter language models that can run (slowly) on a smartphone, and 1–2B param models that run fast on laptops. For XR, this means a headset could potentially carry a local conversational agent that understands voice commands without cloud connectivity. We might eventually get a personal assistant that lives in our AR glasses, knows our context, and runs on a few watts of power. Researchers are already talking about "Large _World_ Models" (LWMs) which are like LLMs but for understanding 3D space – it's a nascent concept, but imagine a model that can observe your environment and predict/plan within it (like an AI that understands the physics of your room and can help you navigate or perform tasks). These too will be shrunken and optimized for AR hardware as they develop.
To sum up the trends: models are getting smaller and faster*, hardware is getting *more AI-friendly, and creative new architectures are emerging that are specifically tailored for the kinds of multimodal, spatial problems XR needs to solve. The gap between what AI can do in the cloud and what it can do on your headset is narrowing each year.
Why On-Device Matters
We've touched on it throughout, but it's worth explicitly stating why on-device AI is so important for XR:
Of course, on-device isn't a free lunch. We need to acknowledge the challenges and trade-offs that come with it, especially for XR:
Despite these challenges, the trajectory is overwhelmingly positive. Every generation of hardware and software is mitigating these issues (through better chips, better tools, and more efficient models as we discussed in the previous section). As a result, the benefits of on-device AI far outweigh the downsides for most XR use cases. Privacy and responsiveness are especially key in making spatial computing something people can trust and rely on daily.
XR Devices and Camera Access APIs
Delivering experiences like the cooking assistant requires that XR headsets have access to their cameras and can run AI algorithms on what they see. Until recently, this was a major hurdle – many consumer VR/MR headsets had cameras for tracking or passthrough, but third-party developers _could not_ directly access the raw camera feed. That's changing fast. Let's look at the landscape of XR devices and how they are opening up their "vision" to developers:
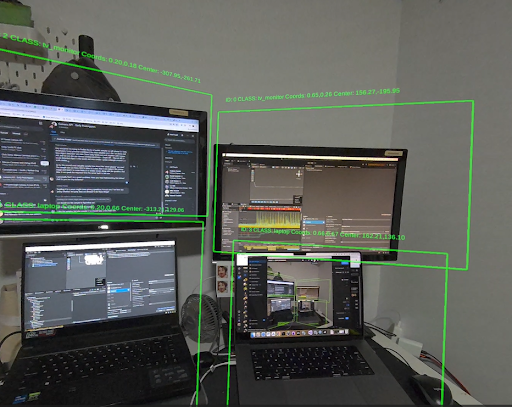
Sentis* and the *Yolov8n model to identify real objects at runtime on Quest 3 devices.
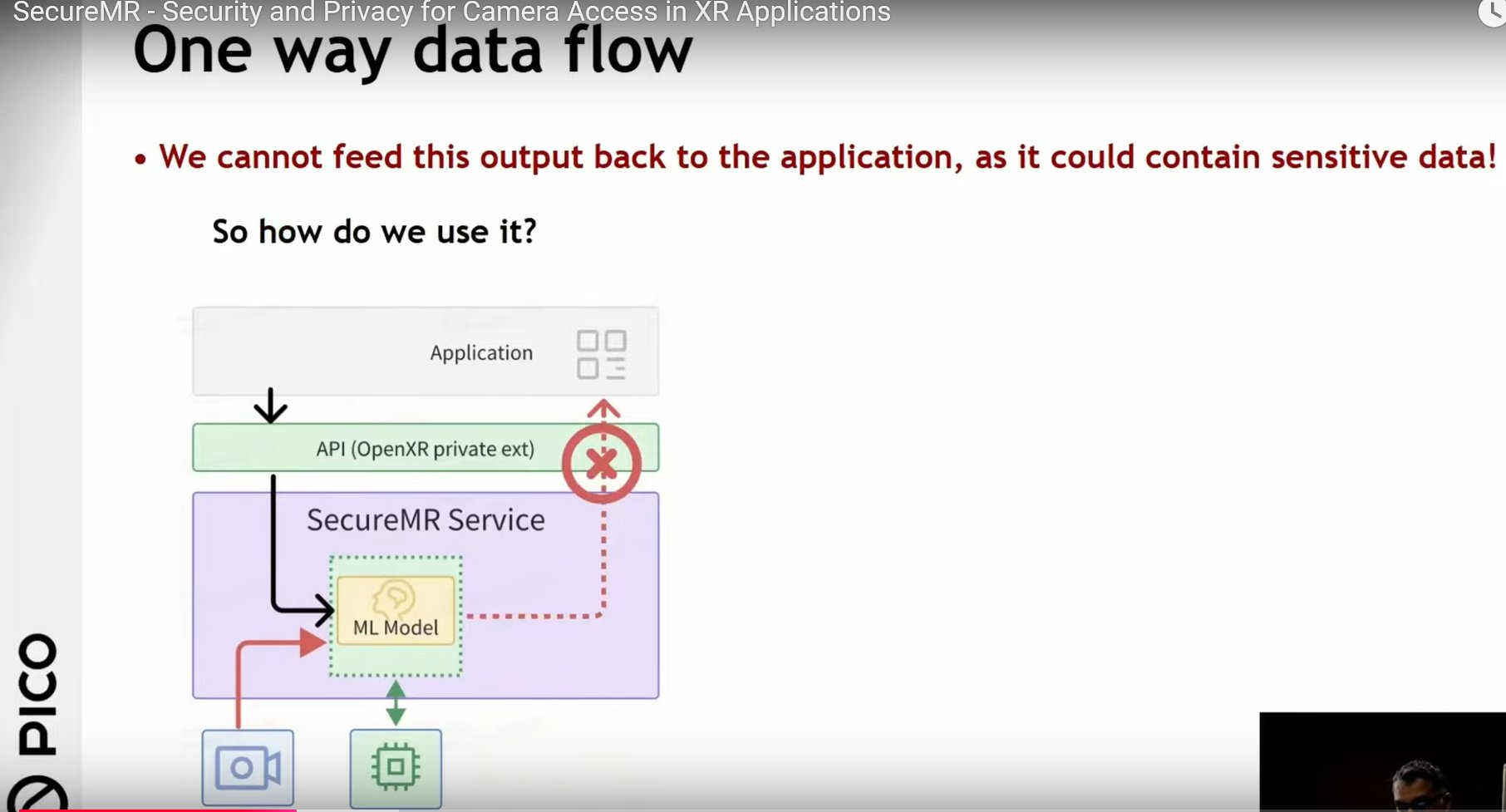
picos camera access flow
The XR device landscape is rapidly evolving to support AI. Meta and Pico are leading the charge in opening camera APIs and promoting on-headset AI processing. Apple is integrating AI tightly but cautiously. HTC is enabling high-quality passthrough and likely rolling out CV features in their Wave SDK. Across the board, the trajectory is clear*: future XR headsets are being designed to be *"spatially aware AI companions" that can see and understand your environment. Even Google, via its Android XR initiatives, has indicated that _passthrough camera access will be part of the Android XR platform_, encouraging developers to "fine tune their mixed reality experiences" with it. The walls between XR and AI are coming down.
Conclusion
XR is poised to become much more than just a display technology – with AI, it transforms into a contextual, intelligent medium. We are moving toward a future where your XR glasses or headset is not just a screen for apps, but an active participant* in your environment: understanding it, annotating it, and even anticipating your needs. The convergence of XR and AI is opening the door to countless new experiences. From the *cooking assistant that sees what you see and helps you step-by-step, to training simulations that understand and correct your technique, to productivity apps that can recognize objects (your whiteboard, your keyboard) and enhance your workflow – the possibilities are wide open. As one industry perspective put it, _"As AI and XR technologies rapidly converge, a revolution led by 'Spatial Intelligence' is quietly unfolding... unlocking infinite possibilities for the XR Metaverse."_ We are at the start of that revolution now.
For developers and tech enthusiasts, the message is: now is the time to experiment with AI on XR devices. The toolchain is ready – APIs like Meta's Passthrough API and Pico's camera access are available (or imminently coming), SDKs like Unity Sentis make it feasible to deploy custom models, and a wealth of pre-trained lightweight models can be adapted to your use case. Whether it's using a vision model to add a layer of understanding to an AR game, or plugging a chatbot into a VR education app for natural voice interaction, or building a context-aware assistant for enterprise workflows – the barriers to entry have fallen. Start with small experiments: for instance, try using Sentis to run an object detection model on Quest 3 and highlight real-world objects in passthrough. Or use an on-device speech recognizer to let users verbally control an AR experience. By building these prototypes, you'll gain insight into performance tuning and user interaction design with AI in XR.
It's also wise to keep an eye on the fast-moving research: new model compression techniques and multitask models are being published frequently (many with open-source implementations you can test). The gap between a research demo and something you can run on a headset is closing rapidly. Who knows – by this time next year, we might have a viable local multimodal assistant running on XR glasses, making the vision of spatially aware AI companions a reality. In the coming years, as form factors shrink towards normal-looking glasses, on-device AI will be even more critical (you won't want to stream video from your smart glasses constantly). Those glasses will need to _whisper prompts in your ear about what's around you_, proactively help out in daily tasks, and do so privately and efficiently.
In conclusion, the fusion of XR and AI is set to redefine how we interact with technology. The inflection point is here: XR devices are gaining the senses and smarts needed for true contextual awareness. For developers, it's an exciting new playground – one where skills in 3D UX design and machine learning can combine to create magical experiences. We've highlighted just one scenario (cooking) among many. As cameras and neural networks become standard issue in XR, we'll see a Cambrian explosion of use cases: education* (a tutor that watches you solve a problem and gives hints), **healthcare** (glasses that monitor your workouts or assist the visually impaired by describing the scene), *enterprise (AI-inspected manufacturing through AR glasses), and beyond. The XR devices of the future won't just render pixels – they'll understand the world and help us navigate it. It's an AI-powered future, and it's going to be an exciting ride for those of us building it. So strap on your XR headset, fire up those neural nets, and start creating the next generation of spatial experiences!
Sources: The insights and examples in this post draw from a range of recent developments and references: Meta's and Pico's official developer docs and announcements on camera access, Unity's documentation on Sentis, academic research on AR cooking assistants, industry analysts on XR + AI convergence, and hands-on reports from XR pioneers. All citations are provided inline for those who want to explore further. Here's to the future of XR with AI – one that is immersive, intelligent, and deeply integrated with the world around us.